14.1 Tablas de contingencia agregadas
Una tabla léxica agregada no es más que una tabla de contingencia en donde las filas son las formas gráficas y las columnas los textos. Las respuestas a preguntas abiertas se pueden definir textos artificiales utilizando partes o pedazos de las respuestas originadas en preguntas cerradas. Existen dos tipos básicos de tablas de contingencia agregadas (Césari, 2007):
- La TC (tabla de contingencia) léxica básica que tiene forma: individuos x formas; comúnmente empleadas en el análisis descriptivo visto en el tema anterior.
- La TC léxica agregada que tiene forma: formas x textos.
Cuando deseamos comparar partes de un documento llamados textos con los perfiles léxicos, la tabla que lo permite es una “tabla léxica agregada”, parecida a la tabla léxica, que contiene las frecuencias de las formas en cada parte (Tusell, 2012; Césari, 2007).
Una forma sencilla de realizar una tabla léxica de contingencia agregada es a través de las siguientes actividades:

Si lo que se desea es también aplicar los métodos de análisis multidimensional, se debe realizar una tabla léxica agregada acorde al siguiente formato:
Formas x Grupos textos, con una notación T. La celda (i, j) de T es la frecuencia con la que se forma, i se encuentra en el grupo j.
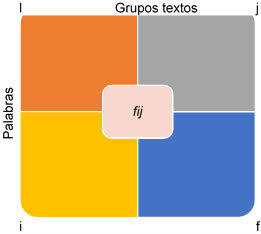
Matriz que recoge el número de veces que la forma i ha sido utilizada en el texto individual, por el conjunto de individuos que eligen la modalidad j. A partir de esta tabla se pueden comparar los perfiles léxicos de los segmentos de población definidos.
La tabla léxica agregada se construye cuando el cuerpo es particionado en textos que se desean comparar.
El propósito al construir la tabla es comparar los perfiles léxicos de los textos en los cuales se segmenta el cuerpo. Esta partición del documento se hace según grupos de clasificación: sexo, edad, estudios, nivel socioeconómico, etc.; o una partición del documento en partes o textos según autor, fecha, etc. La tabla contiene tantas filas como formas, y tantas columnas como modalidades de clasificación (tipologías de los grupos).
Esta categoría de partes del cuerpo —respuestas o textos— es proporcionada por los datos complementarios cualitativos. Incluso al estudiar la tabla léxica base se ha obtenido una nueva variable léxica “tipológica” cuyos cluster o modalidades pueden ser incluidas en esta tabla para en un análisis posterior proyectarlos en el mapa, como ayuda a la interpretación (Césari, 2007).
La construcción de la tabla léxica T puede hacerse a partir de la tabla léxica original, haciendo uso de la matriz X, de Individuos x Modalidades. Cuando se aplican encuestas, la matriz X es construida a partir de las modalidades de la variable de clasificación utilizada. El elemento (i,j) de la matriz X contiene 1 si el individuo i pertenece a la modalidad j y 0 en otro caso.
En este caso la tabla T es el producto T = F’ x X. La fila i de la tabla T corresponde a las subfrecuencias de la forma i en los j textos. Para el estudio diferencial de texto, se puedes utilizar la tabla léxica base “transpuesta”, es decir que en columnas tendremos a cada texto no agrupado y en fila todo el vocabulario.
Esta tabla permitirá agrupar el vocabulario según como se distribuye en cada uno de los textos. No siempre será necesario realizarlo, dependerá de los objetivos del estudio. Pero antes de analizar la tabla léxica agregada se recomienda primero analizar esta tabla considerando los textos individuales que se seleccionan para proyectarlos ilustrativamente. Esta tabla es simétrica a la anterior y el AFCS es el mismo, la idea en este caso es clasificar el vocabulario, no los textos, pero siempre sobre los factores (Pérez, 2004).
Un ejemplo de una tabla de contingencia léxica agregada podría ser el siguiente:
SIGNO PALABRA |
ACUARIO |
ARIES |
CÁNCER |
CAPRIC. |
ESCORP. |
GÉMINIS |
LEO |
… |
PISCIS |
Abierto |
2 |
0 |
0 |
0 |
0 |
1 |
0 |
… |
1 |
Acción |
0 |
3 |
0 |
0 |
0 |
0 |
2 |
… |
0 |
Agua |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
… |
1 |
Amable |
0 |
0 |
0 |
0 |
0 |
2 |
0 |
… |
1 |
… |
|
|
|
|
|
|
|
|
|
Saludable |
3 |
0 |
0 |
1 |
0 |
1 |
0 |
… |
0 |
Así, esta tabla léxica agregada Z contiene perfiles grupos (formas x grupos textos).
Cuando existen una o varias particiones pertinentes del cuerpo, podemos construir, para cada una de ellas, la “tabla léxica agregada” de contingencia que contiene para cada parte, la frecuencia con la que se encuentra una forma en esta parte.
14.2 Distribución de palabras características
El método llamado especificidades de unidades lexicales típicas, consiste en determinar elementos que resultan característicos de un determinado texto cuando llevamos a cabo un estudio comparativo de varios de ellos (Tusell, 2012).
Este carácter específico de una palabra o un segmento para un texto concreto se determina a través de la comparación con un cuerpo más amplio de textos que sirve como referencia. El estudio de varios textos reunidos en un mismo cuerpo, con la intención de encontrar diferencias en los mismos, nos lleva a confrontar la frecuencia con que aparece, en los distintos textos, una palabra o un segmento. Ciertas formas son muy utilizadas en algunos textos, mientras que prácticamente están ausentes de otros. Lo que pretende este método de las “especificidades” es precisamente detectar las palabras que destacan por su reiterada aparición, o por el contrario, por su rareza (Tusell, 2012; Césari, 2007).
Las palabras o segmentos que presentan una especificidad positiva dentro de una parte diferencial del cuerpo son aquellas que se emplean por encima de lo que cabría esperar si las apariciones de esta se distribuyeran aleatoriamente en todo el cuerpo; por el contrario las negativas corresponden a formas que están subutilizadas en relación a su presencia en el cuerpo.
Se busca identificar las palabras “sobrerepresentadas” características en un texto, en comparación con la totalidad. Esto es, comparar la frecuencia relativa de cada una de las palabras en un texto, y en la totalidad del cuerpo, considerada como frecuencia de referencia, utilizando una prueba estadística clásica para emitir el juicio comparativo.
Una prueba comúnmente utilizada es la de Laplace Gaus, centrada y reducida. Ésta traduce la probabilidad, estandarizado de tal forma se puede considerar como palabras características aquellas cuyo valor de test supere el umbral de 1.96 (palabras anormalmente frecuentes). Por debajo de este valor no hay significación estadística (palabras anormalmente poco frecuentes). El valor de test constituye una medida propuesta para la diferencia entre la frecuencia de la palabra en el grupo y la frecuencia de esta misma palabra en el conjunto (Césari, 2007).
Una desventaja de este análisis es que al extraer las palabras características de cada texto o grupo, se ignora totalmente los contextos de las palabras. Por subsanarlo, se busca identificar las respuestas que se puedan considerar características (modales) de cada grupo.
Las respuestas características son particiones íntegras del cuerpo. Una sola frase nunca resumirá la riqueza de un texto como tampoco nunca un único individuo modal será un buen representante de toda una clase de individuos. Dado un grupo de individuos (textos), se puede calcular su perfil léxico medio. Se consideran como respuestas modales de este grupo, las respuestas más próximas a dicho perfil medio, según la distancia de Chi2.
La caracterización anterior puede mejorarse dividiendo la distancia frase -grupo por la media aritmética de las distancias de esta frase a todos los otros grupos. Se suele también seleccionar a las respuestas características siguiendo otro criterio, el criterio del valor de test medio.
Para cada uno de los grupos, se afecta a cada palabra un valor de test que valora su frecuencia en el grupo comparada a su frecuencia en la muestra. Se puede atribuir a cada frase la media de los valores de test de las palabras que la componen. Las respuestas con valor medio más alto serán las más características del grupo. Las unidades lexicales "típicas" se definen por exceso (sobre utilización) o por defecto (sub utilización), según un criterio estadístico que requiere la aplicación del test de chi cuadrado.
Asociaciones de palabras para el estudio diferencial de textos
Es posible obtener un grupo restringido de formas significativas que pueden ser consideradas coocurrentes (derecha o izquierda) del «polo» analizado. A cada una de ellas le corresponde un índice conforme al cual pueden ser ordenadas jerárquicamente, describiendo una red de coocurrencias lexicales, cuya representación consistirá en un grafo de la red lexical del «polo» estudiado. Cada palabra tiene un sistema de "direcciones" donde se registran los lugares del cuerpo en la cual "vive". Estos "lugares" son los contextos elementales, es decir, los segmentos de texto que corresponden aproximadamente a los enunciados. Así pues, las coocurrencias, son las cantidades que resultan del cómputo del número de veces que dos o más elementos lingüísticos (palabras o lemas) "cohabitan", es decir están presentes contemporáneamente, en los mismos contextos elementales (Tusell, 2012; Césari, 2007).
El cómputo de la coocurrencia se hace construyendo tablas cuadradas, o sea con los mismos elementos en filas y en columnas. En términos técnicos, estas tablas se llaman simétricas, ya que las dos partes separadas por la diagonal contienen, especularmente, los mismos valores. El estudio de las relaciones entre coocurrencias, se realiza a través de índices de asociación específicos.
La determinación y medida de las relaciones entre palabras se pueden lograr mediante diferentes métodos. Uno de ellos considera el entorno de cada palabra. Este entorno está integrado por “n” palabras a cada lado de la seleccionada, atribuyéndoseles diferente valor de acuerdo a su proximidad. El conjunto de relaciones cuantificadas permite atribuir a cada palabra un factor de capacidad de relación. Después de realizar la lematización automática del cuerpo, las asociaciones entre palabras hace aparecer una estructura de red, en donde un grupo puede representarse como un grafo conexo entre las palabras más fuertemente asociadas que se convierte en una unidad por eliminación de los vínculos a otras palabras con un menor coeficiente de asociación. El criterio para que una palabra pertenezca a un grupo es que su vínculo a otra palabra sea superior a un cierto umbral o que se acepte hasta un cierto número de palabras.
14.3 Evolución del vocabulario en el tiempo
En el tratamiento de cuerpos o documentos textuales, un objetivo consiste en poner de relieve aquello que varía con el tiempo. Se conocen con el nombre de series textuales cronológicas a cuerpos homogéneos emitidos por una misma fuente textual, en condiciones de enunciación similares que presentan características léxicométricas comparables.
El estudio del crecimiento del vocabulario ofrece una manera de abordar la estructura temporal del cuerpo. El flujo de palabras nuevas no es constante a lo largo de un cuerpo sino que se observa un crecimiento marginal cada vez más débil a medida que el cuerpo se alarga. Es interesante ajustar la curva de crecimiento observada mediante un modelo de correspondiente a un crecimiento regular. El cuerpo se construye extrayendo palabras de una urna del vocabulario general, y de las urnas de vocabulario especializados. Estudios empíricos han mostrado que las palabras generales aparecen frecuentemente al principio del cuerpo y que, a medida que el cuerpo se alarga, la probabilidad de encontrar una palabra general disminuye, y la aparición de una palabra especializada es casi constante. Suponiendo que al extraer una palabra general, la probabilidad de obtener una determinada forma es proporcional a su frecuencia, se propone un modelo que permite no sólo estimar la proporción p de vocabulario especializado, sino también determinar la curva teórica. Este se denomina modelo de partición del vocabulario. Este parámetro p, constituye una medida de la especialización del vocabulario, este es fruto de varios factores como por ejemplo, vocabulario distinto según el período temporal.
Los cambios detectados en el nivel de especialización de un mismo autor o locutor suelen ser significativos. Al someter un cuerpo temporal —segmentado en partes— al análisis de correspondencias, es frecuente obtener un primer eje factorial sobre el cual dichas partes se suceden orneadas en función del tiempo. Dos textos consecutivos son relativamente próximos el uno del otro porque las palabras aparecen y desaparecen progresivamente. Si el tiempo conlleva una renovación pautada del vocabulario y su influencia es predominante, entonces los distintos textos se posicionan sobre el primer plano factorial a lo largo de una curva aproximadamente parabólica. Puede entrar en juego otros factores y alterar la regularidad correspondiente a estos patrones (Tusell, 2012; Césari, 2007).
Cuando se construyen documentos a partir de palabras clave, se obtienen por lo menos cuatro ventajas claramente identificables.
Instrucciones: Haz clic en la imagen para conocer las ventajas.

Para el análisis de discursos o textos, se propone observar los usos del vocabulario en uno o más textos a partir del análisis estadístico. Los mundos lexicales pueden estudiarse entonces a través del análisis de la organización y distribución de las palabras principales coocurrentes en los enunciados simples de un texto.
Su originalidad radica en su principio teórico, el cual guía el desarrollo del tratamiento estadístico de los datos: es la idea de localización de los mundos lexicales que componen el discurso, a través del análisis de las asociaciones de las palabras principales coocurrentes en las frases.
Estas sucesiones repetitivas de palabras asociadas en los distintos fragmentos del texto ayudan a descubrir lazos o asociaciones “temáticas” difícilmente accesibles por medio de un análisis categorial tradicional, centrado principalmente en las frecuencias de categorías y subcategorías elaboradas por el investigador (Tusell, 2012; Césari, 2007).
Es aconsejable conocer bien el texto y localizar los grandes temas que lo componen antes de comenzar la interpretación. Los datos analizados pueden presentar ciertas limitaciones, una de ellas es que al no tomar en cuenta la construcción sintáctica de las frases, sino sólo las palabras reducidas a sus raíces más frecuentemente asociadas entre sí, se pierde el sentido original del texto y se corre el riesgo de hacer algunas interpretaciones equivocadas. Por ejemplo, se puede confundir el significado de la palabra “poder” con el verbo y el sustantivo.






