13.1 Glosario de términos frecuentes
La minería de datos textuales nace de la escuela francesa que busca métodos de análisis multidimensionales exploratorios. Entre las primeras aplicaciones se desarrolló el análisis de correspondencias que veremos más adelante en este mismo tema. Posteriormente, otros autores consideraron la importancia de tratar preguntas abiertas con métodos más automáticos que la post-codificación manual y que en la mayoría de los casos aún se sigue realizando (Luque, 2012).
La minería de datos textuales consiste en aplicar métodos; partiendo siempre del análisis descriptivo, el análisis de correspondencias y la clasificación a tablas específicas, creadas a partir de los datos textuales.
Estos métodos se ven complementados con métodos propios del dominio textual como pueden ser los glosarios de palabras, las concordancias y la selección del vocabulario más específico de cada texto, permitiendo así una herramienta comparativa de los mismos. Un método de análisis ya probado en estudios textuales es la aptitud que éstos tienen para elaborar tipologías mediante el recuento de las formas gráficas (Pérez, 2004).
Estos métodos presentan la ventaja de estudiar perfiles lexicales en su conjunto, y por lo tanto, tomar en cuenta redes de autocorrelaciones bastante finas. De esta manera consiguen llegar bastante lejos en el estudio de los textos, a la vez que guardan una total independencia de la lengua tratada (Hair, 2007).
La lexicometría o estadística lexical es aquella en la que el área de interés está representada por la lista de todas las formas lexicales acompañadas, cada una, de un efectivo numérico: su frecuencia de empleo (Tusell, 2012; Césari, 2007). La importancia de la lexicometría radica en lo siguiente:
- Las frecuencias son una herramienta estadística básica para la descripción cuantitativa.
- La frecuencia está matemáticamente relacionada con la estimación de la probabilidad de una unidad en un conjunto de datos.
- La frecuencia es muy productiva cuando atraviesa los distintos niveles de análisis lingüístico (grafema, morfema, forma, clase gramatical, tipo léxico, caso, etc.)
- El cálculo de frecuencias permite observar distintos niveles de “comunalidad” o “especificidad” entre dos o más conjuntos de análisis.
Podríamos decir que cualquier tipo de dato textual es susceptible de ser analizado:
- Respuestas de asociación a un concepto
- Entrevistas de todo tipo (abiertas-cerradas; grupales-individuales)
- Textos literarios
- Historias de vida
- Notas de campo de observación etnográfica
- Discursos políticos
- Documentos en Web
- Noticias de diarios
La única condición es que sea texto.
Algunas opciones sencillas de análisis para cada tipo de fichero son:
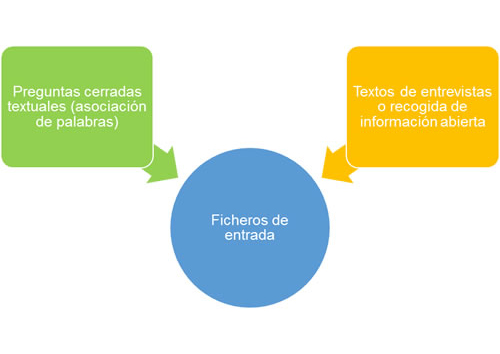
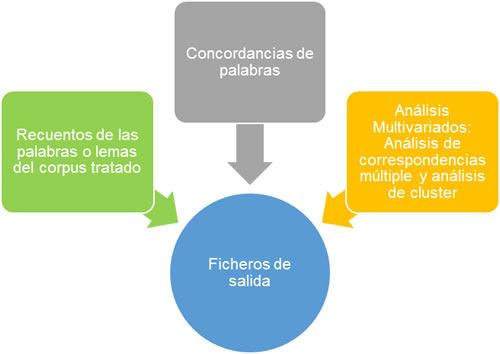
Al final de este tema (en el glosario) se encuentran detallados los principales términos de la minería de datos textuales.
13.2 Análisis descriptivo
Este punto de partida del análisis suele conocerse como índice lexical y tiene naturaleza jerárquica cuando las formas estén ordenadas por frecuencias decrecientes o "alfabético".
El índice lexical jerárquico —cuando se explora un discurso— permite establecer una primera imagen sintética del contenido del cuerpo o texto estudiado. Todo discurso emplea un número limitado de formas con frecuencia elevada y, por otro lado, una cantidad importante de formas con escasa frecuencia, es posible construir un inventario de palabras que representan una gran parte del repertorio lexical de un cuerpo o texto (Tusell, 2012; Césari, 2007).
Sin embargo, la lingüística moderna ha acumulado una enorme cantidad de material procedente de la observación y descripción de hechos, relaciones, leyes y comparaciones que han terminado desbordanado la capacidad de tratamiento de los problemas por métodos tradicionales y han elevado la metodología basada en modelos estadísticos, que, supuestamente, proporcionan una mayor amplitud de interpretaciones.
Obviamente, no es posible efectuar inferencias sólidas a este nivel, pues lo que se percibe es sólo el sistema de "preferencias" lexicales del locutor. Lo que se observa en los rangos superiores del índice jerárquico es el conjunto de puntos de densidad del discurso, sobre todo en cuanto a su matriz referencial global (en términos generales habrá siempre un predominio de sustantivos que vehiculan la información intencionalmente) (Césari, 2007).
Por otro lado, los problemas de polisemia hacen que sea necesario relativizar toda interpretación hasta no verificar en contexto el uso de los términos.
La minería de datos textuales conlleva la creación de diccionarios específicos para cada análisis, ya que las palabras tienden a mantener en todo contexto un cierto "núcleo" semántico estable. Por ejemplo, cuando un político hace mención en su discurso de la palabra "patria", se está refiriendo casi con seguridad al colectivo nacional de pertenencia que genera identidad entre sus connacionales. Por supuesto, la "connotación" podrá variar de locutor a locutor o de político en político, e incluso de enunciado a enunciado; aun así, se tratará en todos los casos de la designación de una "zona" referencial específica.
El trabajo descriptivo con frecuencias léxicas se vuelve mucho más interesante cuando se establecen contrastes entre varios cuerpos o textos o entre las diversas partes de un mismo cuerpo. En el índice lexical jerárquico, la frecuencia sólo sirve para dar lugar a un gradiente: el empleo de una palabra es "significativo" cuando su posición jerárquica en la lista indica la existencia de una "preferencia" con respecto a las otras opciones lexicales de las que el locutor disponía (por ejemplo, en un discurso presidencial, Menem "prefirió", en general, el término "país" al término "patria" para designar al colectivo nacional) (Tusell, 2012; Césari, 2007).
También ciertos aspectos de la enunciación pueden ser indagados a través de un acceso lexical. Por ejemplo, la observación de las frecuencias de empleo de los pronombres personales y posesivos de la primera persona. El estudio de las formas verbales conjugadas en primera persona puede aportar otros elementos relevantes en lo que concierne a la enunciación.
13.3 Análisis de correspondencias
La aplicación del Análisis Factorial (AF) en el campo de la minería de datos textuales se centra principalmente en el algoritmo estadístico del Análisis Factorial de Correspondencias (AFC).
El AFC es un método descriptivo (no explicativo) —dentro de los métodos multivariantes de interdependencia— que permite visualizar los datos, que pueden ser de naturaleza cualitativa o cuantitativa, mediante la representación de una nube de puntos en un espacio de dimensiones reducidas, en función de las distancias geométricas entre los puntos (Luque, 2012; Césari, 2007).
El proceso de análisis se efectúa siguiendo cuatro etapas (Tusell, 2012; Césari, 2007):
Instrucciones: Haz clic en cada componente para ver el detalle
Como consecuencia de todo el proceso se obtiene un mapa de posicionamiento entre todos los atributos considerados en los dos conjuntos tratados (variables fila y variables columna). El resultado es, pues, un solo conjunto homogéneo que incluyen todos los elementos de la matriz.
Así pues, de esta manera se puede obtener una representación sintética de los atributos de tipificación considerados y las marcas analizadas, en sus principales ejes de diferenciación. La proyección en el plano de los puntos individuales que constituyen los atributos del producto permitirá interpretar la significación de los ejes factoriales obtenida.
El AFC es una técnica de interdependencia que facilita tanto la reducción dimensional de una clasificación de objetos (marcas, empresas, personas, palabras, frases, textos etc.) sobre un conjunto de atributos y el mapa perceptual de objetos relativos a estos atributos (Tusell, 2012; Césari, 2007).
Debido a que los investigadores se enfrentan constantemente a la necesidad de “cuantificar datos cualitativos” que encuentran en variables nominales, el AFC ajusta tanto los datos no métricos como los que presentan relaciones no lineales, siendo así de gran utilidad.
En su forma más básica, el AFC emplea una tabla de contingencia que es la tabulación cruzada de dos variables categóricas. A continuación transforma los datos no métricos en un nivel métrico y realiza una reducción dimensional y un mapa perceptual.
El AFC proporciona una representación multivariante de la interdependencia de datos no métricos que no es posible realizar con otros métodos multivariantes (Luque, 2012; Pérez, 2004).