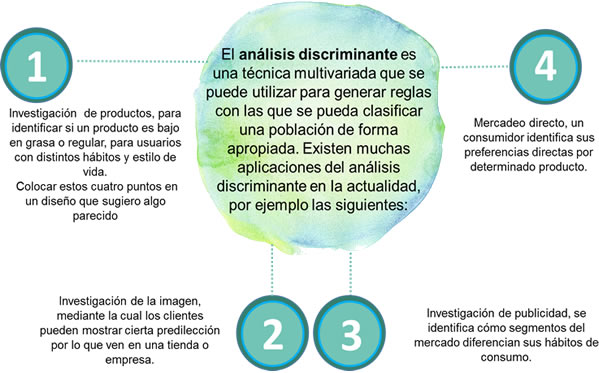
10.1 Conceptos y objetivo básico del análisis discriminante
Malhotra (2008) describe el análisis discriminante como una técnica multivariante que se puede utilizar para generar reglas con las que se puede hacer la clasificación de una población agrupada. El análisis discriminante es similar al análisis de regresión, a excepción de que, en este caso, la variable dependiente es categórica (no métrica) en vez de continua. Por esta razón, el análisis discriminante nos permitirá predecir la pertenencia a una clase, de una observación particular, con base en un conjunto de variables predictoras.
Los objetivos de esta técnica son los siguientes (Malhotra, 2008):
Instrucciones: Haz clic para ver a detalle cada dimensión
A continuación se presentan los supuestos que fundamentan esta técnica:
- Cada grupo debe ser una muestra de una población normal multivariada.
- Las matrices de covarianza poblacional deben ser iguales, es decir, la dispersión de los datos con respecto a su media y la dispersión de los datos teniendo en cuenta las dos variables como si fueran una sola, son iguales.
10.2 Clasificación del análisis discriminante: simple y múltiple
Las técnicas de análisis discriminante se describen usando la cantidad de categorías que posee la variable de criterio. Si se tienen dos categorías, la técnica se conoce como análisis discriminante de dos grupos o análisis discriminante simple. Si se tienen más de dos categorías, la técnica se conoce como análisis discriminante múltiple. La diferencia es que en el caso de dos grupos sólo se generará una función discriminante, mientras que en el análisis discriminante múltiple pueden generarse más de una función discriminante (Luque, 2012).
Dado que el tratamiento de análisis discriminante es similar al análisis de varianza y al análisis de regresión, es conveniente hacer un comparativo de las técnicas, como se muestra en la siguiente tabla:
|
|
ANOVA
(Varianza) |
Análisis
regresión |
Análisis
discriminante |
Semejanzas |
Número de variables dependientes |
Una |
Una |
Una |
Número de variables independientes |
Múltiples |
Múltiples |
Múltiples |
Diferencias |
Naturaleza de las variables dependientes |
Métrica |
Métrica/binaria |
Categórica/binaria |
Naturaleza de las variables independientes |
Categórica |
Métrica |
Métrica |
El análisis discriminante de dos grupos, en el que la variable dependiente sólo tiene dos categorías, está muy relacionado con el análisis de regresión múltiple. Si la variable dependiente es métrica con valores 0 o 1 (binaria), entonces se puede hacer el tratamiento de análisis de regresión, que es mucho más simple para resolver. A este modelo se le denomina modelo logit. (Luque, 2012).
10.3 Cálculo de la función discriminante
El modelo de análisis discriminante supone combinaciones lineales del siguiente tipo (Malhotra, 2008):
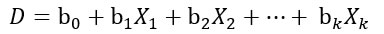
Donde:
D = calificación discriminante
b = coeficiente o peso discriminante
X = variable independiente o predictiva
Los coeficientes se calculan de forma tal que el grupo difiera, tanto como sea posible, en los valores de la función discriminante, lo cual ocurre cuando es máxima la razón de la suma de cuadrados entre grupos y la suma de cuadrados intragrupos de las puntuaciones discriminantes.
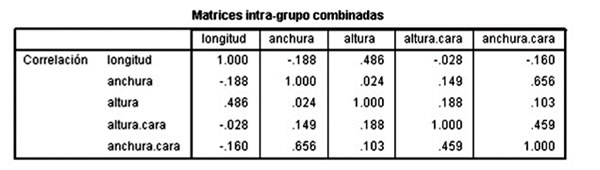
Esas diferencias se obtienen a partir de la matriz de relaciones que se puede obtener en el paquete estadístico que estemos utilizando, en el cual se encuentra como matriz de correlación (ver cuadros en PSPP en el ejemplo) (Pérez, 2004). La matriz de correlación se presenta en PSPP de la siguiente forma:
Matrices intragrupo combinadas
|
Ingreso |
Viaje |
Vacación |
Tamaño |
Edad |
Correlación |
Ingreso |
1.000 |
.197 |
.091 |
.089 |
-.014 |
Viaje |
.197 |
1.000 |
.084 |
-.017 |
-.197 |
Vacación |
.091 |
.084 |
1.000 |
.070 |
.017 |
Tamaño |
.089 |
-.017 |
.070 |
1.000 |
-.043 |
Edad |
-.014 |
-.197 |
.017 |
-.043 |
1.000 |
Las suposiciones del análisis discriminante se trata de que cada uno de los grupos es una muestra de una población normal multivariada y todas las poblaciones tienen la misma matriz de covarianza (Malhotra, 2008). El papel de estas suposiciones y los estadísticos pueden entenderse mejor si se revisa el algoritmo para realizar el análisis discriminante:
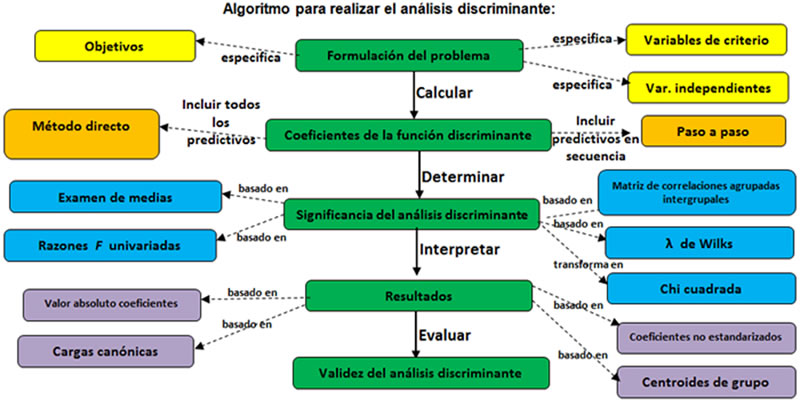
Formulación del problema. En la formulación del problema se identifican los objetivos del análisis discriminante, las variables de criterio y las variables independientes. Las variables de criterio tendrán que ser al menos dos variables mutuamente excluyentes entre sí. Cuando la variable dependiente se basa en una escala de intervalo o de razón, se tendrá que convertir en categoría en primer lugar. Por ejemplo, en una encuesta hacia la simpatía a cierto partido político, en la escala de 7 puntos podrá categorizarse como desfavorable (1, 2, 3), neutra (4) o favorable (5, 6, 7), de tal forma que sea posible graficar la distribución de la variable dependiente y formar grupos de igual tamaño.
El siguiente paso es dividir la muestra en dos partes. Una parte de la muestra, llamada muestra de análisis o de estimación, se utiliza para calcular la función discriminante. Otra parte de la muestra, llamada muestra de validación o de exclusión, se reserva para la validación de la función discriminante. Es muy conveniente repetir la validación del análisis discriminante a fin de asegurarnos de los resultados adecuados. En este caso conviene dividir la muestra en forma diferente y volver a validar. Cuando utilizamos un paquete computacional, muchas veces realiza la validación de forma automática (Luque, 2012; Malhotra, 2008; Hair, 2007; Pérez 2004).
Cálculo de coeficientes de la función discriminante
Para determinar los coeficientes de la función discriminante existen dos métodos generales:
1. Método directo
El método directo significa calcular la función discriminante de forma tal que todos los predictivos se incluyan al mismo tiempo, sin importar el peso del predictivo.
2. Análisis discriminante paso a paso
En el análisis discriminante paso a paso las variables predictivas se introducen en secuencia con base en la habilidad del investigador a discriminar entre grupos.
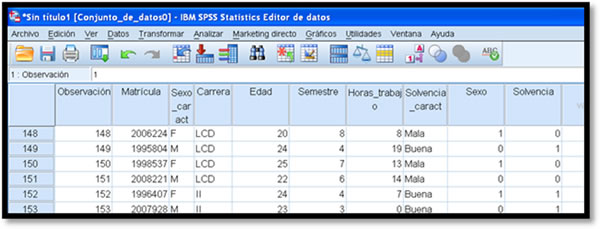
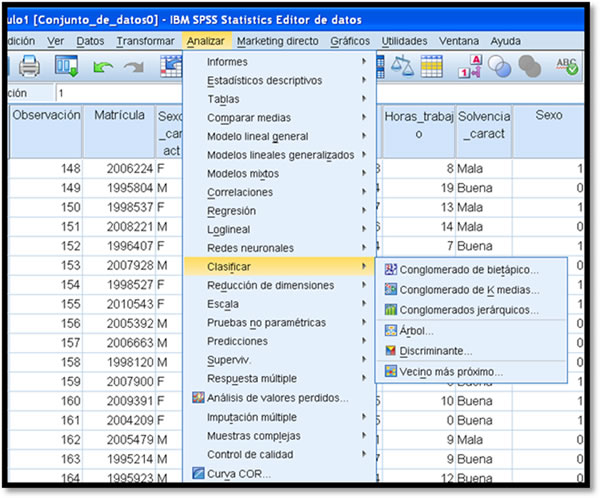
En el paquete computacional (PSPP, Excel u otro) se anotan dos tablas: una con los datos a discriminar y otra con los datos que darán validez al análisis. Estos datos se seleccionan de forma aleatoria.
Para revisar un ejemplo, haz clic aquí.
Pruebas de significancia estadística
Significancia de análisis discriminante. Es indispensable realizar alguna de estas pruebas a fin de determinar si las funciones discriminantes calculadas son estadísticamente significativas (Malhotra, 2008; Hair, 2007; Pérez, 2004). Existen varias pruebas que podemos realizar, a continuación se presentan algunas de ellas:
- El examen de medias, en éste se espera que se rechace la hipótesis nula de que todas las medias sean iguales.
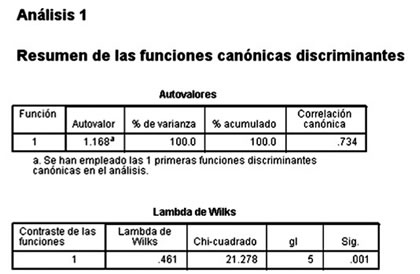
- La λ de Wilks, es el producto de la λ univariada de cada función (y es la prueba que realiza el paquete PSPP). El cálculo del nivel de significancia se basa en la transformación del estadístico en una chi cuadrada. Si la λ es pequeña, entonces discrimina mucho; la variabilidad total se debe a las diferencias entre grupos, no a las diferencias dentro de grupos.
- El cálculo del estadístico F, se basa en una aproximación a la distribución de la razón de probabilidad, en donde se compara, para cada variable, las desviaciones de las medias de cada uno de los grupos con respecto a la media total (y es la prueba que hace SAS). Si F es grande para cada variable, entonces las medias de cada grupo están muy separadas y la variable discrimina bien.
- La matriz de correlaciones agrupadas intergrupales indica correlaciones bajas entre los predictivos, de tal forma que cada variable será independiente.
Interpretación de resultados. La interpretación de los pesos o coeficientes discriminantes es similar al método de regresión múltiple. El valor del coeficiente para un predictivo depende de los otros incluidos en la función discriminante. Existen distintos elementos para poder interpretar los resultados en un análisis multivariante, algunos de ellos son los siguientes:
- Las cargas canónicas: representan la varianza que el predictivo comparte con la función. Cuanto mayor sea la magnitud de una correlación estructural, mayor será la importancia del predictivo correspondiente.
- Los coeficientes estandarizados: representan las intercorrelaciones entre los predictivos, y se usan como multiplicadores cuando las variables se han estandarizado con una media de 0 y una varianza de 1.
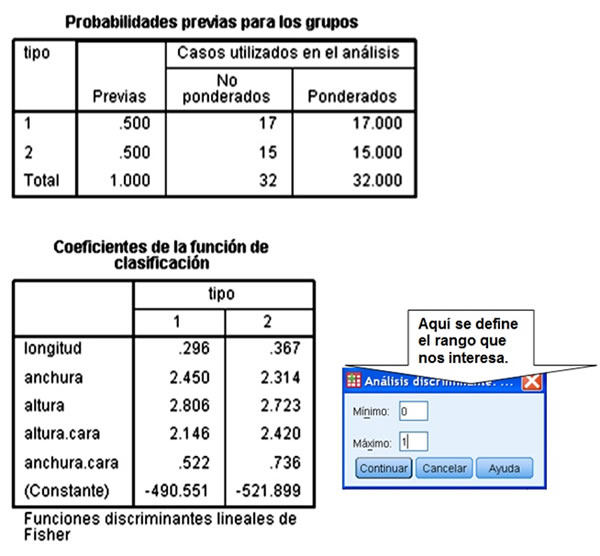
- Los coeficientes no estandarizados: sirven simplemente para clasificación.
- Los centroides de grupo: indican el valor de la función discriminante evaluada en las medias del grupo. Los signos de los coeficientes asociados son positivos, mientras que los no asociados son negativos.
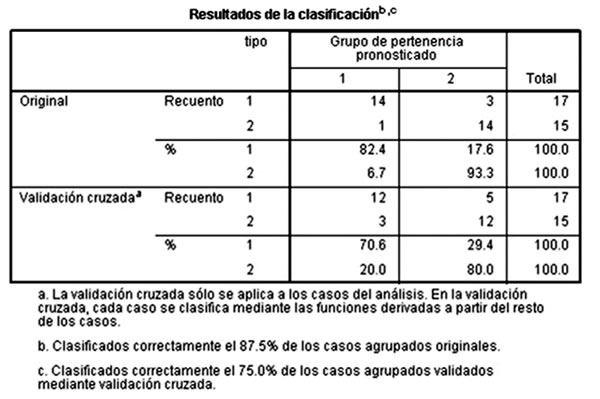
Validación del modelo
El dato que se use en la validez de análisis discriminante dependerá del paquete computacional utilizado. En el caso de PSPP se ofrece la opción de validación cruzada con exclusión, lo cual significa que cada vez se excluye a un encuestado y el modelo se utiliza para predecir los datos sobre este encuestado. Eso da solidez a los cálculos de los estadísticos. Al final del análisis aparece la siguiente leyenda: “Clasificados correctamente el…% de los datos agrupados originales…, “Clasificados correctamente el…% de los datos agrupados validados”, con lo cual podemos garantizar la validez de nuestro análisis (Malhotra, 2008).
Finalmente, armamos la función discriminante a partir de los coeficientes no estandarizados de nuestro análisis, tal y como aparecen en la tabla de coeficientes de clasificación en cuestión que arroja PSPP, de manera que obtendremos los datos para formar una expresión del tipo:
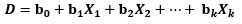
Si alguno de los coeficientes es significativamente menor al resto, se puede descartar influir en los grupos.
En conclusión, el análisis discriminante es una técnica muy útil para poder separar o eliminar aquellas variables que no sean indispensables para caracterizar una muestra. También el análisis discriminante es útil para determinar si hay diferencia entre varios grupos de datos, a partir de una variable categórica dependiente de otras variables métricas independientes.